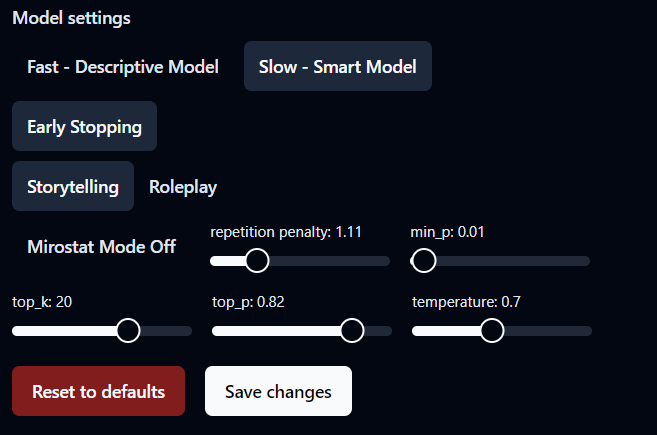
Ever wondered what these settings are? I am going to try to answer what they do and how you can use them on this page.
For every token (word or sub-word) generated by the model, the model has to select from a lot of probable tokens. Each probable token has a probability attached to it by the model. The settings above dictate how we select the next token from all the probable tokens.
Let's start with the temperature. Temperature controls the randomness of text generation. The higher the temperature, the more creative and random the replies will be. High temperatures will make your character stray away from their persona. Low temperatures are more deterministic, a little repetitive, and will make the replies consistent with the character's persona.
min_p or minimum probability is a filter that filters out tokens that are less probable than below the min_p threshold. That's a fancy way of saying we throw out all the tokens with a probability less than 1% if the min_p is 0.01. min_p controls the quality of the token meets our minimum standard, in this case, it is 1%. If you set the min_p too high like 0.5 (50%), it will make the responses more deterministic since now there can at most be only 2 tokens to be selected for each new token generation.
top_p gives the model a ceiling above which it can't go. If top_p is 0.82 (82%), the model will add up the probability of all tokens and will stop considering more tokens when the cumulative reaches 82%. Before adding the probabilities, top_p sorts all the probabilities in descending order so the most probable token is considered first, then the second, and so on. This setting is useful, to weed out the long tail of low-probability tokens improving the quality of the generation. In all honesty, this setting should be called cum_p considering it is cumulative probability cutoff but we all know why the researchers who invented it, didn't want to want to call it that.
repetition_penalty is an interesting one. This might be the only setting that looks at the old tokens that were generated to select the new one. Tokens that are repeated a lot in the previous generation get penalized to reduce repetition. A penalty of 1 is no penalty. The more you increase this setting, the more the model will try to not repeat itself but also in pursuit of not repeating it will start considering low probable tokens which otherwise the model wouldn't have gone for. Anything between 1.05 and 1.2 is a healthy penalty range.
top_k selector selects the top N tokens from the sample. If the top_k is 20, it will select the 20 most probable tokens.
Early stopping. This setting was added later on to curb the length of responses from the AI. When turned on, the responses will be a lot shorter. If you are into story characters, I'd suggest you turn this off. How does this work you ask? It considers periods, exclamation marks, and question marks as stopping criteria. If there are 4 such criteria in the response, it will stop generating the response and respond with the generated text.
And lastly, we have Mirostat. When it is turned on you will see that you can no longer select the temperature. This is because Mirostat selects the temperature dynamically on each new token generation. I'd advise you to turn this setting on and chat with your characters and see if you like it.
For most characters, using the defaults (or simply turning Mirostat Mode On), will suffice. Changing these values is a more advanced layer of customization and not something you necessarily have to worry about on initial character creation